Datenbank-Blockierungen finden, aufzeichnen, auswerten und Datenbankabfragen optimieren.
Autor: Michael R. Friebel
Blockierungen und damit akut verlangsamte Abfragen sind eine häufige Ursache für Datenbank Performanceprobleme. In diesem Artikel geht es darum, wie diese Abfragen und deren Ursachen identifiziert und ausgewertet werden können um die Datenbank zu optimieren.
SQL Server arbeitet standardmäßig im sogenannten ISOLATION Level READ COMMITTED. Es geht hier um die Isolation von Prozessen, also Abfragen oder SQL Befehle, die zur gleichen Zeit auf die gleichen Daten in einer SQL Server Datenbank zugreifen.
READ COMMITTED bedeutet. Abfragen, Prozesse oder andere User dürfen nur committete Daten sehen.
Wenn Dir die Problematik nicht klar ist solltest Du dir, bevor Du weiterliest, meine Youtubevideos, die die Problematik ausführlich erklären ansehen.
https://youtu.be/umvQCuIHdHg SQL Server Datenbank Transaktionen Einführung zum nachvollziehen ganz simpel erklärt - Teil 1
https://youtu.be/UKOGn6IEE_4 SQL Server Datenbank Transaktionen - Blockierungen Verstehen, Erkennen, Lösen 😎👌- Teil 2
Eigentlich habndelt es sich bei SQL Server um ein ganz normales Verhalten. Daten die geändert werden müssen für diesen Zeitraum für andere Prozesse gesperrt werden um Dirty Reads etc. zu vermeiden. Problematisch wird es nur, wenn diese Sperren ewig gehalten werden, da das ganze System nicht performant genug ist oder Transaktionen ewig offen gehalten werden.
Natürlich kann man jetzt anführen, dass es ja den Isolation Level Snapshot Isolation oder Snapshot Read Committed gibt aber ein mal schnelles umswitchen in diese Isolation Level bei einer Produktivanwendung sollte man tunlichst vermeiden, da wir bei einer Snapshotisolationsstufe vom pessimistischen ins optimistische Sperrverhalten wechseln und Anwendungen hier komplett anders reagieren können. Aber dies ist ein anderes Thema.
Wenn ich in meinem System vermute, dass ich sehr viele Blockierungen habe, dann stellt sich die nächste Frage. Welche Abfragen, die auf Grund von Sperren warten müssen, sind das? Welche Befehle sind im Blockierungsprozess mit eingebunden?
Wie in den Videos erklärt, gehören ja immer mindestens zwei dazu. Einer der die Sperre verursacht und der andere der auf die Daten die gerade gesperrt sind zugreifen möchte.
Noch einmal: Sperren sind etwas völlig normales. Abfragen die auf eine Sperre treffen müssen warten bis die Sperre aufgelöst wird.
In einem performanten SQL Server System werden bei einer OLTP (Online Transactional Processing - Häufiges Daten ändern und häufiges lesen) Anwendung in der Regel tausende Sperren innerhalb kürzester Zeit gesetzt. Das ist auch alles kein Problem. Die Sperren müssen bloß sehr schnell wieder aufgelöst werden.
Ok kommen wir zum Punkt. Was sind mögliche Symptome für eine Datenbank die unter langen Blockierungen (Abfragen warten auf Auflösung von Sperren) leidet.
Symptome:
- Abfragen die mal schnell sind und dann auf einmal wieder sehr lange brauchen - Sinusverhalten
- Abfragen, die definitiv hängen also nicht fertig werden bei bestimmten Konstellationen oder Programmierfehlern
Lösung - Schneller machen, damit die Sperre schneller wieder weg ist :
- Sperren können beschleunigt werden, indem die Sperren Verursacher also eventuelle DML (Insert, Update, Delete) Befehle die die Sperren setzen beschleunigt werden
- Tuning des SQL Servers oder der Datenbank durch gezielte Konfiguration bzw. Setzen von Indizes
- mit dem Hersteller oder Entwickler sprechen, das hier eine Lösung gefunden werden muss
Die große Frage die sich stellt ist jetzt wie kann ich die Abfragen finden, die die Sperren verursachen oder am Sperrprozess beteiligt sind.
Ziel ist es also die ABfragen einzufangen, die auf Grund einer Blockierung zu lange warten müssen.
Hier kommen die Extended Events zum Einsatz. Wenn Dir nicht klar ist, was das ist findest Du unter folgenden Link eine Einführung: https://learn.microsoft.com/de-de/sql/relational-databases/extended-events/quick-start-extended-events-in-sql-server?view=sql-server-ver16
Kurz und knapp. Mit Extended Events kann man Ereignisses also Leistungsdaten abgreifen und auafzeichnen. Die Möglichkeiten sind hier sehr vielfältig.
Vorgehensweise jetzt:
Wir legen für uns fest, ab welcher Dauer welche Abfragen die nicht weiterkommen (also gerade warten), da eine Sperre gesetzt ist aufgezeichnet werden sollen um diese zu identifizieren. 5 Sekunden, 10 Sekunden oder 60 Sekunden? Das musst Du wissen.
Dieser Sekundenwert muss SQL Server mitgeteilt werden und man macht dies mit dem folgenden Skript. Dieses Skript stellt über die SQL Server Systemprocedure sp_configure die Optionen ein. Also melde Dich in SSMS (SQL Server Managment Studio) als Administrator an und führe das Skript aus.
Wenn Dir nicht klar ist, was hier passiert, solltest Du Dir zuvor https://learn.microsoft.com/de-de/sql/relational-databases/system-stored-procedures/sp-configure-transact-sql?view=sql-server-ver16 ansehen was mit sp_configure gemacht wird.
-- die Anzeige der erweiterten Optionen aktivieren
EXEC sp_configure 'show advanced options', 1 ;
GO
RECONFIGURE ;
GO
-- definieren ab wieviel Sekunden ein blockierter Prozess als verdächtig gilt
-- hier 10 sekunden
-- ab sql2022 heisst Paramer 'blocked process threshold (s)'
EXEC sp_configure 'blocked process threshold', '10';
RECONFIGURE
GO
RECONFIGURE
GO
-- die Anzeige der erweiterten Optionen wieder zurücksetzen
EXEC sp_configure 'show advanced options', 0 ;
GO
RECONFIGURE ;
GO
Anschließend wird jetzt eine Extended Event Session angelegt, die die Abfragen einfängt, die länger als 10 Sekunden (wir haben den Wert von 10 Sekunden oben mit sp_configure festgelegt) dauern.
-- Dieses Skript legt eine Extended Event Session [blockierungen_finden] an und Startet diese auch sofort.
-- !!!! Bitte unbedingt den Pfad für die Xel Datei anpassen !!!!
CREATE EVENT SESSION [blockierungen_finden] ON SERVER
ADD EVENT sqlserver.blocked_process_report(
ACTION(sqlserver.client_app_name,
sqlserver.client_hostname,
sqlserver.database_name)) ,
ADD EVENT sqlserver.xml_deadlock_report (
ACTION(sqlserver.client_app_name,
sqlserver.client_hostname,
sqlserver.database_name))
ADD TARGET package0.asynchronous_file_target
(SET filename = N'c:\analyse\gefundene_blockierungen.xel',
metadatafile = N'c:\analyse\gefundene_blockierungen.xem',
max_file_size=(65536),
max_rollover_files=5)
WITH (MAX_DISPATCH_LATENCY = 5SECONDS)
GO
-- Session wird mit nachfolgendem Befehl auch gleich gestartet
ALTER EVENT SESSION [blockierungen_finden] ON SERVER
STATE = START;
Die Extended Event Session kann auch im SQL Server Management Studio angelegt werden oder nach Ausführung des Skripts im SSMS betrachtet, gelöscht, gestartet oder gestoppt werden. Hierzu wird auf die Session mit der rechten Maustaste geklickt und die Optionen werden im erscheinenden Kontextmenü ausgewählt. (siehe nachfolgende Abbildung).
![Ansicht der Extended Events Session [blockierungen_finden] im SSMS](https://biservices.io/images/posts/blockierungen_finden/ssms_extended_event_session.jpg)
Wie dem auch sei, ab jetzt werden alle Abfragen die auf Grund einer Sperre länger als 10 Sekunden zur Ausführung brauchen in der Datei gefundene_blockierungen.xel aufgezeichnet. Ebenfalls werden auch mit dieser Session sogenannte Deadlocks aufgezeichnet. Was ein Deadlock genau ist erkläre ich Dir in diesem Video https://youtu.be/ygYeRl5nFcM
Eine .xel Datei ist eine Binärdatei. Diese kann aber im SSMS angesehen werden. Durch Doppelklick auf diese Datei wird diese bei installiertem Management Studio angezeigt. In der Spalte blocked_process findet sich ein umfangreiches XML Konstrukt, dass alle Informationen zum jeweils blockierten Prozess enthält. Dieses Konstrukt enthält die am Blockierten Process beteiligten SQL Anweisungen inklusive weiterer nützlicher Informationen. (siehe folgende Abbildung)
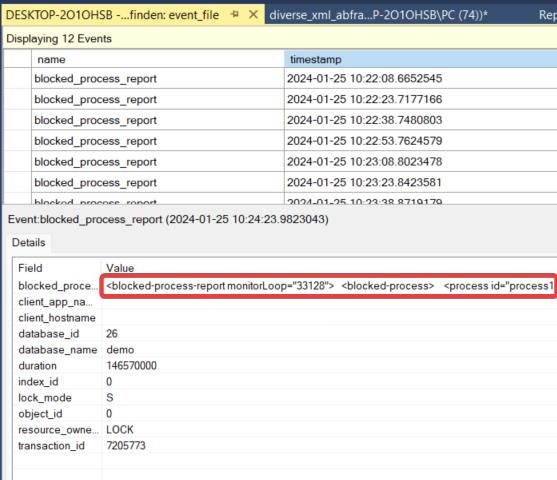
Analyse der XEL Daten
Wie können die Daten in der XEL Datei jetzt am besten ausgewertet werden?
Ich möchte hier aber einige Vorgehensweisen zeigen wie mit XEL Dateien gearbeitet wird.
Variante 1:
Klar kann ich diese im Management Studio betrachten und gegebenenfalls ist dies für den einen oder anderen auch ausreichend. Hierzu einfach im SSMS mit der rechten Maustaste auf package0.event_file klicken und -View Target Data…- auswählen.
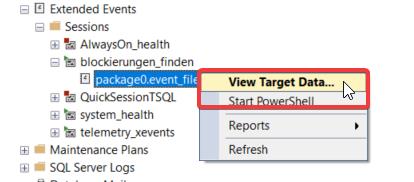
Ich erhalte dann folgende tabellarische Darstellung im SSMS (siehe nachfolgende Abbildung). In der Spalte blocked_process stehen jetzt alle Informationen zur Blockierung. Diese können mit der rechten Maustaste angeklickt werden und dann in einen übersichtlichen Editor kopiert werden.
Die Daten im XML sehen entsprechend in etwa so aus, wie in der folgenden Abbildung dargestellt. Es ist klar ersichtlich welches der Blockierende Prozess und welches der blockierte Prozess sprich SQL Kommando ist. Viele weitere nützliche Informationen sind in dem XML in Form von Attributen und Elementen enthalten.
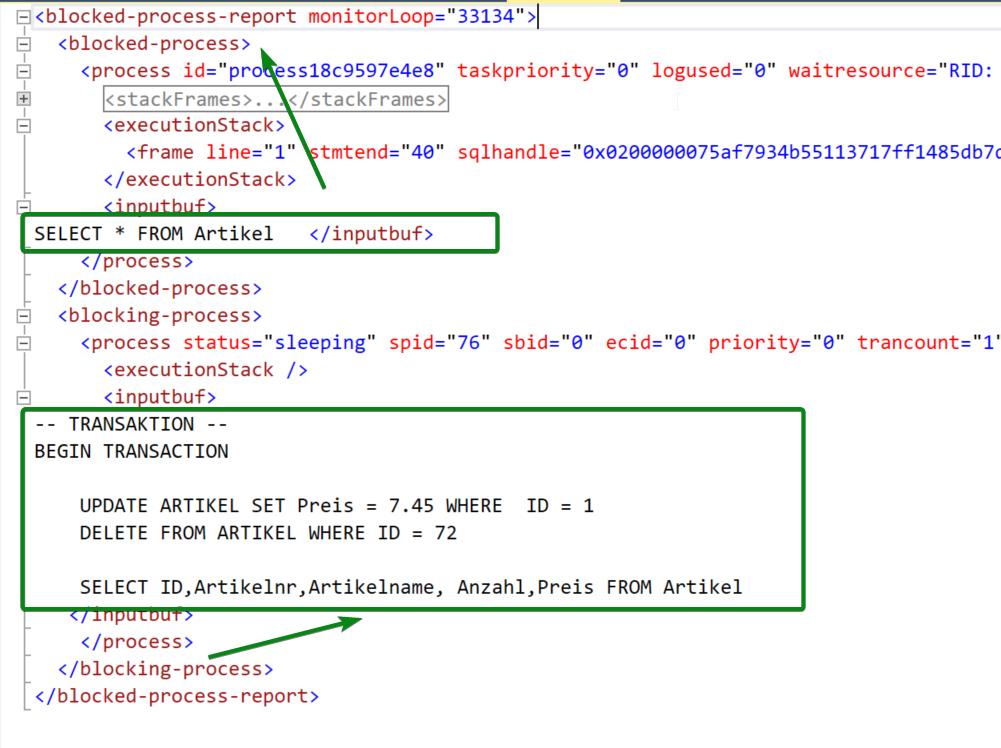
Variante 2: Importieren der Daten in eine SQL Server Tabelle zur besseren Auswertung
Wem diese Art der Auswertung nicht reicht, kann die Daten aus der Xel Datei auch in eine entsprechende SQL Server Tabelle in einer Datenbank (in unserem Beispiel demo) speichern und dann durch entsprechende Abfragen über alle Rows und den entsprechenden XML Inhalten abfragen.
Es folgt der T-SQL Code zum import der Daten aus der XEL Datei c:\analyse\blocked.xel (Pfad bitte entsprechend anpassen) in die Tabelle analyze_pool.
WITH events_cte AS (
SELECT
xevents.event_data,
DATEADD(mi,
DATEDIFF(mi, GETUTCDATE(), CURRENT_TIMESTAMP),
xevents.event_data.value(
'(event/@timestamp)[1]', 'datetime2')) AS [event time] ,
xevents.event_data.value(
'(event/action[@name="client_app_name"]/value)[1]', 'nvarchar(128)')
AS [client app name],
xevents.event_data.value(
'(event/action[@name="client_hostname"]/value)[1]', 'nvarchar(max)')
AS [client host name],
xevents.event_data.value(
'(event[@name="blocked_process_report"]/data[@name="database_name"]/value)[1]', 'nvarchar(max)')
AS [database name],
xevents.event_data.value(
'(event[@name="blocked_process_report"]/data[@name="database_id"]/value)[1]', 'int')
AS [database_id],
xevents.event_data.value(
'(event[@name="blocked_process_report"]/data[@name="object_id"]/value)[1]', 'int')
AS [object_id],
xevents.event_data.value(
'(event[@name="blocked_process_report"]/data[@name="index_id"]/value)[1]', 'int')
AS [index_id],
xevents.event_data.value(
'(event[@name="blocked_process_report"]/data[@name="duration"]/value)[1]', 'bigint') / 1000
AS [duration (ms)],
xevents.event_data.value(
'(event[@name="blocked_process_report"]/data[@name="lock_mode"]/text)[1]', 'varchar')
AS [lock_mode],
xevents.event_data.value(
'(event[@name="blocked_process_report"]/data[@name="login_sid"]/value)[1]', 'int')
AS [login_sid],
xevents.event_data.query(
'(event[@name="blocked_process_report"]/data[@name="blocked_process"]/value/blocked-process-report)[1]')
AS blocked_process_report,
xevents.event_data.query(
'(event/data[@name="xml_report"]/value/deadlock)[1]')
AS deadlock_graph
FROM sys.fn_xe_file_target_read_file
('C:\analyse\blocked*.xel',null,null, null)
CROSS APPLY (SELECT CAST(event_data AS XML) AS event_data) as xevents
)
SELECT
CASE WHEN blocked_process_report.value('(blocked-process-report[@monitorLoop])[1]', 'nvarchar(max)') IS NULL
THEN 'Deadlock'
ELSE 'Blocked Process'
END AS ReportType,
[event time],
CASE [client app name] WHEN '' THEN ' -- N/A -- '
ELSE [client app name]
END AS [client app _name],
CASE [client host name] WHEN '' THEN ' -- N/A -- '
ELSE [client host name]
END AS [client host name],
[database name],
COALESCE(OBJECT_SCHEMA_NAME(object_id, database_id), ' -- N/A -- ') AS [schema],
COALESCE(OBJECT_NAME(object_id, database_id), ' -- N/A -- ') AS [table],
index_id,
[duration (ms)],
[database_id],
lock_mode,
COALESCE(SUSER_NAME(login_sid), ' -- N/A -- ') AS username,
CASE WHEN blocked_process_report.value('(blocked-process-report[@monitorLoop])[1]', 'nvarchar(max)') IS NULL
THEN deadlock_graph
ELSE blocked_process_report
END AS Report
into analyze_pool
FROM events_cte
ORDER BY [event time] DESC ;
Auswerten der soeben importierten Daten mittels SQL Abfragen
Wenn die Daten in dieser Tabelle stehen, dann können die Daten mittels Select ausgewertet werden. Dis macht sich besonders gut wenn größere Datenmengen anfallen.
Anbei einige Beispielkommandos zum Ausführen in SSMS, die die Tabelle [demo].[dbo].[analyze_pool] in Kombination mit dem darin enthaltenen XML abfragen.
/****** Skript für SelectTopNRows-Befehl aus SSMS ******/
------------------------------
-- ELEMENTINHALTE ABFRAGEN ---
------------------------------
-- Anzeige XML elementebene
SELECT TOP (1000) [Report].query('blocked-process-report/blocked-process/process/inputbuf') FROM [demo].[dbo].[analyze_pool]
-- anzeigen eines XML Elementinhaltes mitteils node() funktion
SELECT TOP (1000) [Report].value('(blocked-process-report/blocked-process/process/inputbuf/node())[1]','nvarchar(max)') FROM [demo].[dbo].[analyze_pool]
-- anzeigen eines XML Elementinhaltes mitteils node() funktion UND suche mittels LIKE nach '%FETCH%'
SELECT [Report].value('(blocked-process-report/blocking-process/process/inputbuf/node())[1]','varchar(100)') as spalte1 FROM [demo].[dbo].[analyze_pool]
where [Report].value('(blocked-process-report/blocking-process/process/inputbuf/node())[1]','varchar(100)') like '%FETCH%'
-- ohne node funktion anzeigen des wertes eines XML elements
SELECT TOP (1000) [Report].value('(blocked-process-report/blocking-process/process/inputbuf)[1]','nvarchar(max)') FROM [demo].[dbo].[analyze_pool]
-- EXISTS wenn vohanden dann 1 oder wenn nicht 0 zurück (also true oder false)
-- existiert das element process überhaupt
SELECT [Report].exist('/blocked-process-report/blocking-process/process') FROM [demo].[dbo].[analyze_pool]
-- existiert das element egal auf welcher ebene im XML
SELECT [Report].exist('//process') FROM [demo].[dbo].[analyze_pool]
-- oder existiert das element egal auf welcher ebene im XML Trancount
SELECT [Report].exist('//trancount') FROM [demo].[dbo].[analyze_pool]
-- oder existiert das attribut element egal auf welcher ebene im XML Trancount
SELECT [Report].exist('//@trancount') FROM [demo].[dbo].[analyze_pool]
-- oder existiert das attribut im process element ?
SELECT [Report].exist('//process/@trancount') FROM [demo].[dbo].[analyze_pool]
-- Weitere Examples
-- DATE
SELECT [Report].exist('/blocked-process-report/blocking-process/process[(@lastbatchstarted cast as xs:date?) eq xs:date("2002-01-01Z")]')
FROM [demo].[dbo].[analyze_pool]
SELECT [Report].exist('/blocked-process-report/blocking-process/process[(@lastbatchstarted cast as xs:date?) eq xs:date("2021-03-01Z")]') as spalte1
FROM [demo].[dbo].[analyze_pool] order by spalte1 desc
SELECT *, [Report].exist('/blocked-process-report/blocking-process/process[(@lastbatchstarted cast as xs:date?) eq xs:date("2021-03-01Z")]')
FROM [demo].[dbo].[analyze_pool]
where [Report].exist('/blocked-process-report/blocking-process/process[(@lastbatchstarted cast as xs:date?) eq xs:date("2021-03-01Z")]') = 1
SELECT *, [Report].exist('/blocked-process-report/blocking-process/process[(@lastbatchstarted cast as xs:date?) eq xs:date("2021-03-01Z")]')
FROM [demo].[dbo].[analyze_pool]
where [Report].value('(/blocked-process-report/blocking-process/process/@lastbatchstarted)[1]','datetime2') < '2021-03-01T14:21:11.750'
-- anzeigen eines XML Elementinhaltes mitteils node() funktion
SELECT TOP (1000) [Report].value('(blocked-process-report/blocked-process/process/inputbuf/node())[1]','nvarchar(max)') FROM [demo].[dbo].[analyze_pool]
-- suche in der entsprechenden Elementebene mittels CONTAINS nach SELECT und FETCH gibt mit exists zurück ob 1 oder 0
SELECT *, [Report].exist('/blocked-process-report/blocking-process/process/inputbuf[contains(.,"SELECT")]') FROM [demo].[dbo].[analyze_pool]
SELECT *, [Report].exist('/blocked-process-report/blocking-process/process/inputbuf[contains(.,"FETCH")]') FROM [demo].[dbo].[analyze_pool]
SELECT *, [Report].value('(/blocked-process-report/blocking-process/process/@lastbatchstarted)[1]','varchar(100)')
FROM [demo].[dbo].[analyze_pool]
-- ATTRIBUTE DATETIME ABFRAGEN
SELECT *, [Report].value('(/blocked-process-report/blocking-process/process/@lastbatchstarted)[1]','date')
FROM [demo].[dbo].[analyze_pool]
--where [Report].value('(/blocked-process-report/blocking-process/process/@lastbatchstarted)[1]','date') > '2021-03-01'
where [Report].value('(/blocked-process-report/blocking-process/process/@lastbatchstarted)[1]','datetime2') = '2021-03-01T14:21:11.750'
-- BETWEEN
SELECT *, [Report].value('(/blocked-process-report/blocking-process/process/@lastbatchstarted)[1]','datetime2')
FROM [demo].[dbo].[analyze_pool]
--where [Report].value('(/blocked-process-report/blocking-process/process/@lastbatchstarted)[1]','date') > '2021-03-01'
where [Report].value('(/blocked-process-report/blocking-process/process/@lastbatchstarted)[1]','datetime2')
BETWEEN '2021-03-01T14:21:11.750' AND '2021-03-05T14:21:11.750'
---------------------
-- ATTRIBUTE ABFRAGEN
---------------------
-- ohne node funktion anzeigen des wertes eines XML elements
SELECT TOP (1000) [Report].value('(blocked-process-report/blocking-process/process/inputbuf)[1]','nvarchar(max)') FROM [demo].[dbo].[analyze_pool]
Du hast jetzt gezeigt bekommen, wie Du blockierende Prozesse und die dahinter liegenden SQL Befehle finden und auswerten kannst. Im nächsten Schritt heißt es jetzt, zu hinterfragen, warum diese Prozesse sich blockieren.
- Ist es vielleicht eine nicht abgeschlossene Transaktion die nie beendet wird auf Grund eines Programmierfehlers?
- Oder ist einfach nur ein ewig lang dauerndes Update oder Delete auf Grund von fehlenden Indizes? Auch Updates haben in der Regel eine Where Klausel zum finden der Daten.
- werden Prozesse ungünstig zueinander Parallel gestartet? Zum Beispiel ein Rechnungslauf, der auch Nachts laufen könnte?
–Viel Spaß beim Auswerten, finden und natürlich optimieren Ihrer blockierten Prozesse–